Всем известно, что SEO (поисковое продвижение) начинается со сбора семантического ядра (СЯ). Буквально каждый мануал, курс, видеоурок, вебинар или книга начинаются со сбора ключевых слов для продвижения. Создается впечатление, что, не имея готового СЯ, продвигать сайт невозможно. Так, будто 95% успеха зависит от чистоты и полноты списка ключевых слов.
Так ли это? Попробуем разобраться.
Начнем с описания классического процесса сбора семантики, от которого перейдем к методу «без семантического ядра». Сразу оговоримся, что речь в статье пойдет в большей степени о коммерческих тематиках.
Как обычно собирается СЯ
Порядок действий при сборе семантического ядра упрощенно выглядит так:
- Подбор маркерных запросов. Они же базовые маски: названия разделов и товаров, синонимы, конкуренты, мозговой штурм и так далее.
- Парсинг всех источников: Яндекс.Вордстат, Keyword Planner, подсказки, Метрика, Вебмастер, Search Console, базы ключевых слов и другие.
- «Чистка» ключевых слов: по частотности, минус-словам и так далее.
Прекрасный фундаментальный подход. Но он имеет два существенных недостатка:
- Долго. Чем больше сайт, тем более объемный список ключевых слов. Временные затраты на его сбор растут в геометрической прогрессии.
- Это все равно неполное семантическое ядро. Примерно 40% всех запросов уникальны и никогда не будут найдены. Еще некоторый процент невозможно найти, например, из-за ограничений в 7 слов в Яндекс.Вордстат. Вы точно сталкивались с этим на практике. Например, есть тщательно собранное ядро, а переходы идут по другим ключевым словам (часто очень похожим).
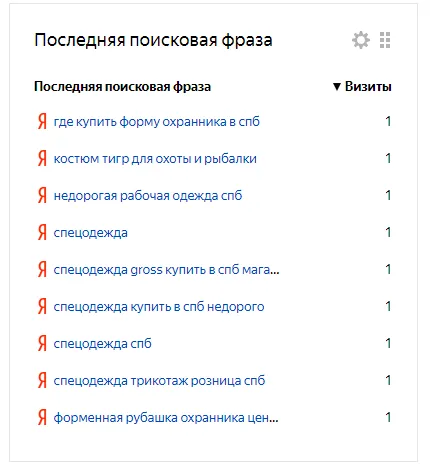
Люди уникальны и формируют свои потребности по-разному
Что делается с семантикой дальше? Выполняется кластеризация. И тут обнаруживается, что множество слов в различных кластерах повторяются. Почему так происходит?
Кластеры разные - слова одинаковые
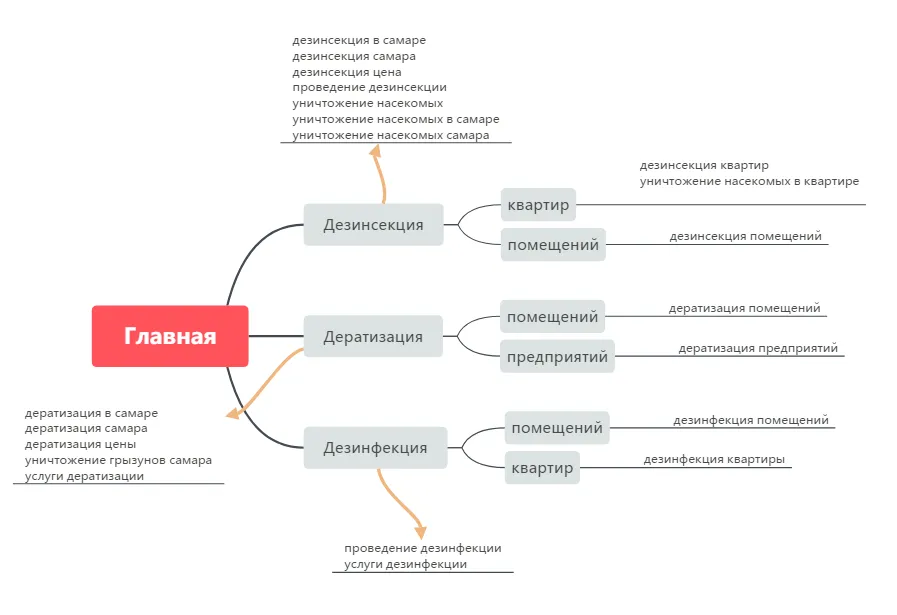
Как строится спрос
Как бы ни были разнообразны товары и услуги, паттерны спроса на них очень похожи. Обычно коммерческий запрос строится по принципу:
Название товара/услуги
+
Уточнение товара/услуги (может отсутствовать)
+
Транзакционные и тематические слова/действия/топонимы (может отсутствовать)
Примеры из различных тематик:
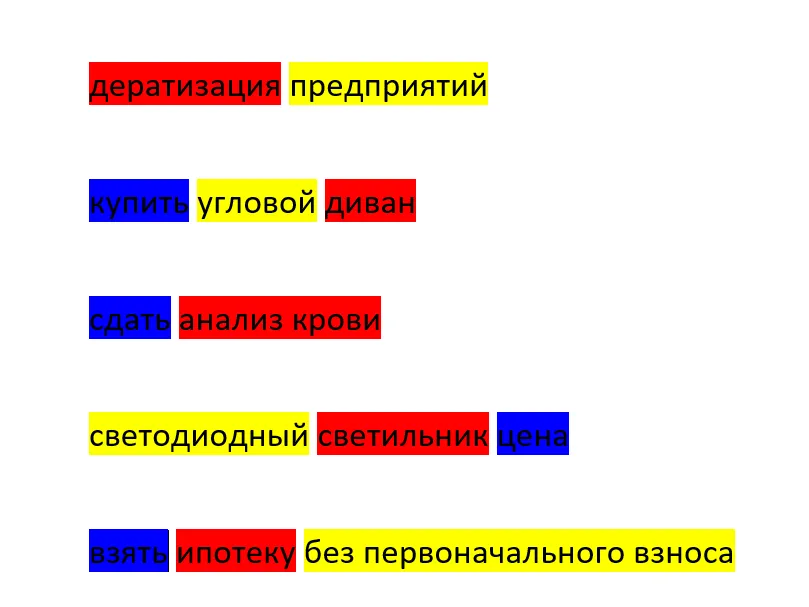
Порядок может меняться, слова сильно зависят от тематики, но принцип сохраняется
Вернемся к кластеризации. Ее мы обычно используем для принятия двух глобальных решений в разрезе SEO (поискового продвижения):
- какие новые страницы создавать на сайте;
- как оптимизировать все страницы на сайте (title, h1, текст и т.д.).
Но если паттерн один и тот же, а внутри одной тематики слова постоянно повторяются, зачем весь этот долгий и кропотливый процесс сбора СЯ? Почему бы сразу не определить слова, составляющие паттерны спроса в нужной тематике?
Как это сделать на практике
- Находим несколько маркерных слов, наиболее явно характеризующих вашу тематику (предполагаемые ВЧ). Можно начать с нескольких названий товаров, разделов и услуг. Собирать здесь всю номенклатуру и синонимы не нужно, так как это слабо повлияет на конечный вид паттерна.
- Собираем по этим словам, а также по сайту и сайтам нескольких конкурентов, данные из «быстрых» источников:
- выгрузка запросов из Яндекс.Вебмастера и Google Search Console
- выгрузка запросов из Яндекс.Метрики и Google Analytics
- выгрузка запросов из готовых баз (Букварикс, Пастухов)
- выгрузка запросов из сервисов анализа конкурентов (Megaindex, Serpstat, Spywords)
- Все найденные запросы лемматизируем и производим сортировку по встречаемости лемм в запросах. Есть множество бесплатных инструментов для этого, удобнее всего сделать в Key Collector, инструменте «Анализ групп». Более продвинутый вариант – с сортировкой по суммарной частотности запросов с использованием каждой леммы, но это требует сбора частотности по всем запросам.
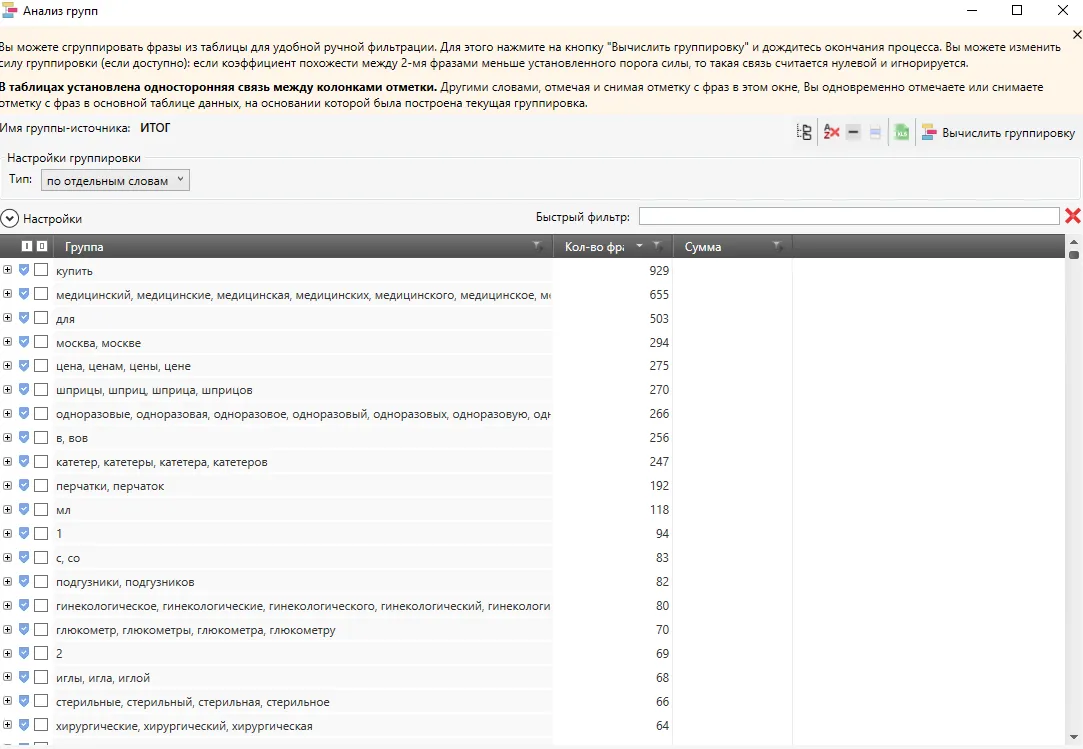
Леммы для сайта медицинских товаров
- Определяем вручную для каждой леммы, чем она является:
- название товара/услуги
- уточнение товара/услуги
- транзакционные и тематические слова/действия/топонимы
- Используем их в шаблонах для дальнейшей оптимизации сайта:
- уточнения товаров/услуг – это потенциальные новые страницы: разделы и тегирование;
- транзакционные и тематические слова/действия/топонимы – это слова для использования в шаблоне оптимизации (title, h1, текст, блоки и т.д.).
Лемм может быть очень много, именно поэтому они изначально отсортированы по встречаемости. Чем больше лемм будет проработано по такому списку, тем глубже погружение в тематику.
Преимущества такого подхода
- Скорость. Метод позволяет максимально быстро охватить большую часть семантики и оптимизировать сайт под нее. Конечно, работа по всему сайту «под одну гребенку» не лишена неточностей: часть уточнений и слов будут неприменимы к некоторым группам страниц. Такая оптимизация – это своего рода MVP (минимально жизнеспособный продукт) в SEO (поисковом продвижении).
- Полнота. С другой стороны, подход позволяет сделать оптимизацию под слова, которых не будет в обычном семантическом ядре, но которые могут быть в тех самых 40% уникальных невидимых запросов. На примере одной из картинок выше.
Использование общих лемм, а не готовых кластеров привело бы здесь к множеству новых идей:
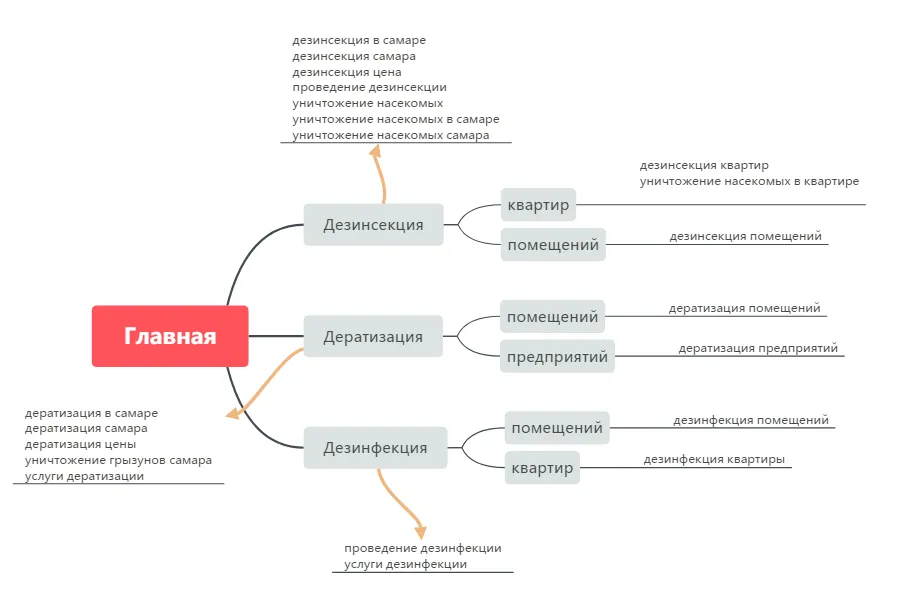
- создание страницы «Дератизация квартир»;
- создание страниц «Дезинсекция предприятий» и «Дезинфекция предприятий»;
- использование в оптимизации страниц про дезинфекцию слов «самара», «цены».
Спрос на такие страницы и запросы может существовать.
- Прогнозирование. Мы работаем с некоей «прогнозной семантикой», так как анализируем только часть существующей номенклатуры, на основе которой делаем выводы для всего сайта в целом. Эти выводы могут оказаться тем спросом, которого еще нет, но который может быть сформирован в будущем.
- Уменьшение объема работ в будущем. Методика отлично подходит к концепции итерационного продвижения. Можно сначала сделать шаблонное MVP оптимизации и сразу получать результат, пока выполняются другие долгие работы. При этом к моменту, когда вы дойдете до «индивидуальной проработки» в каждом кластере, может оказаться, что часть запросов и не нуждается в этом.
Пример из нашей практики: на сайте интернет-магазина есть категория товаров «Маслобензостойкие шланги». Шаблонный подход привел нас к тому, что title страниц категорий сделали таким:
title: {Название_раздела} – купить в Москве, цена в интернет-магазине
то есть в данном случае:
title: Маслобензостойкие шланги – купить в Москве, цена в интернет-магазине
Прошло 1-2 месяца, пока мы пришли к ручному анализу в данном кластере и собрали его семантику:
бензостойкий шланг
купить маслобензостойкий шланг
маслостойкий шланг
рукав мбс
шланг маслобензостойкий
шланг мбс
Казалось бы, как много формулировок мы не охватили в исходном title и изначальная оптимизация почти ничего не должна дать. Но оказывается, все эти запросы уже в ТОП-5 в Яндексе. Поисковые системы совершенствуются и пытаются перейти от слов к смыслу, понять, что «маслобензостойкий=бензостойкий=маслостойкий=мбс», а «шланг=рукав». Конечно, они это делают не идеально. Поэтому дополнительное использование синонимов поможет улучшить результат. :)
- Подход хорошо сочетается с другой техникой – сбором семантики из заведомо более крупного региона для охвата большего числа ключевых слов. Например, для построения структуры сайта про ремонт смартфонов в Тольятти на основе московской семантики. В итоговом сформированном паттерне спроса придется только заменить топоним.
Вместо послесловия
Описанный в статье подход, конечно же, не является чем-то абсолютно новым. Если вы успешно практикующий специалист по поисковому продвижению (SEO), вам наверняка приходилось делать что-то подобное, например, при составлении масок метатегов или написании шаблона текста для карточек товаров. Но почему-то не говорят, что это можно и нужно сделать еще до полноценного сбора семантического ядра.
Это не призыв отказываться от сбора семантики. Однако полный сбор ключевых фраз, доскональная чистка, кластеризация – во многих случаях не первоочередная задача. А в каких-то тематиках ее и вовсе можно отложить «до лучших времен», работая по шаблонам спроса.
P.S. Раскрыть данную тему меня подтолкнул аудит очередного интернет-магазина, где спустя 4 месяца кропотливой работы оптимизатор прописал отличные title на 1000/2000 категорий, вида «Купить диван недорого в Москве, цены на диваны от производителя с доставкой». А тем временем на остальных 1000 категорий висят title=H1 и покорно ждут своей очереди… Почему бы не сделать шаблон для всех категорий в первый же день продвижения?
